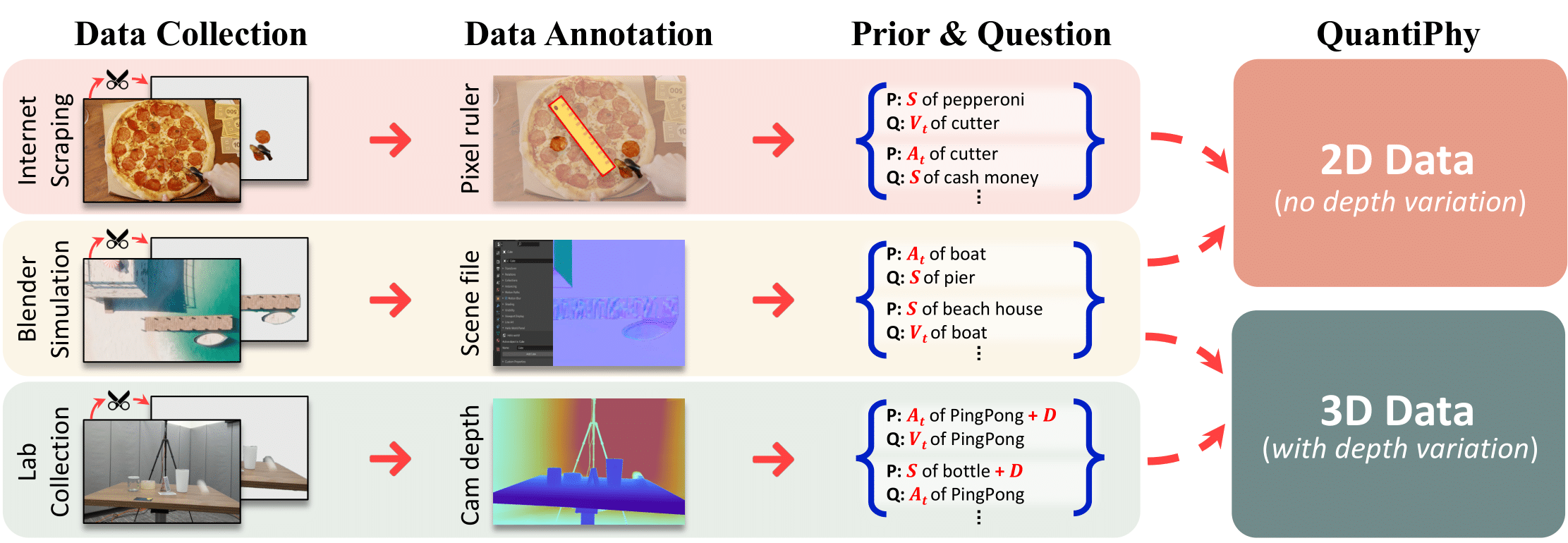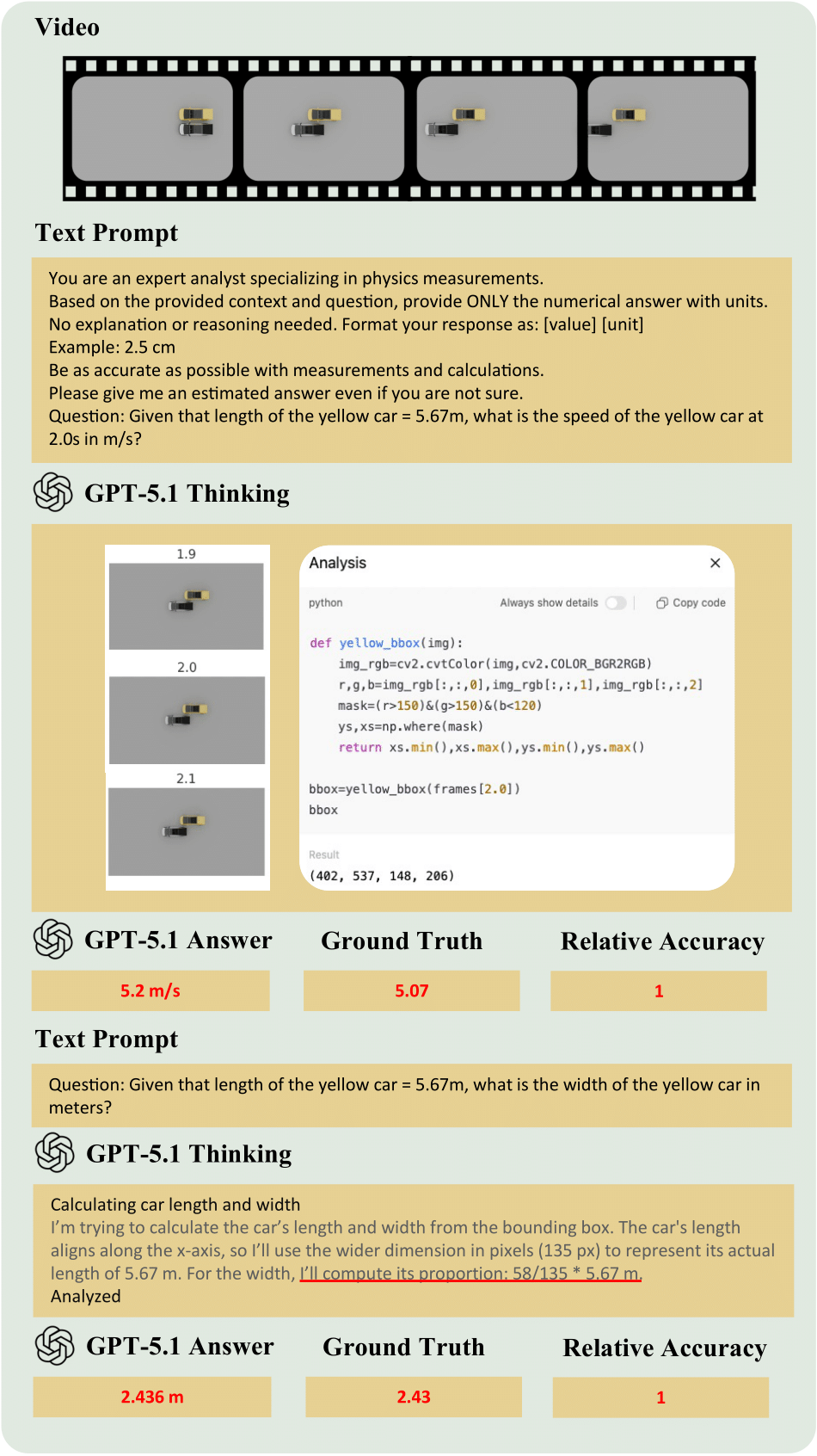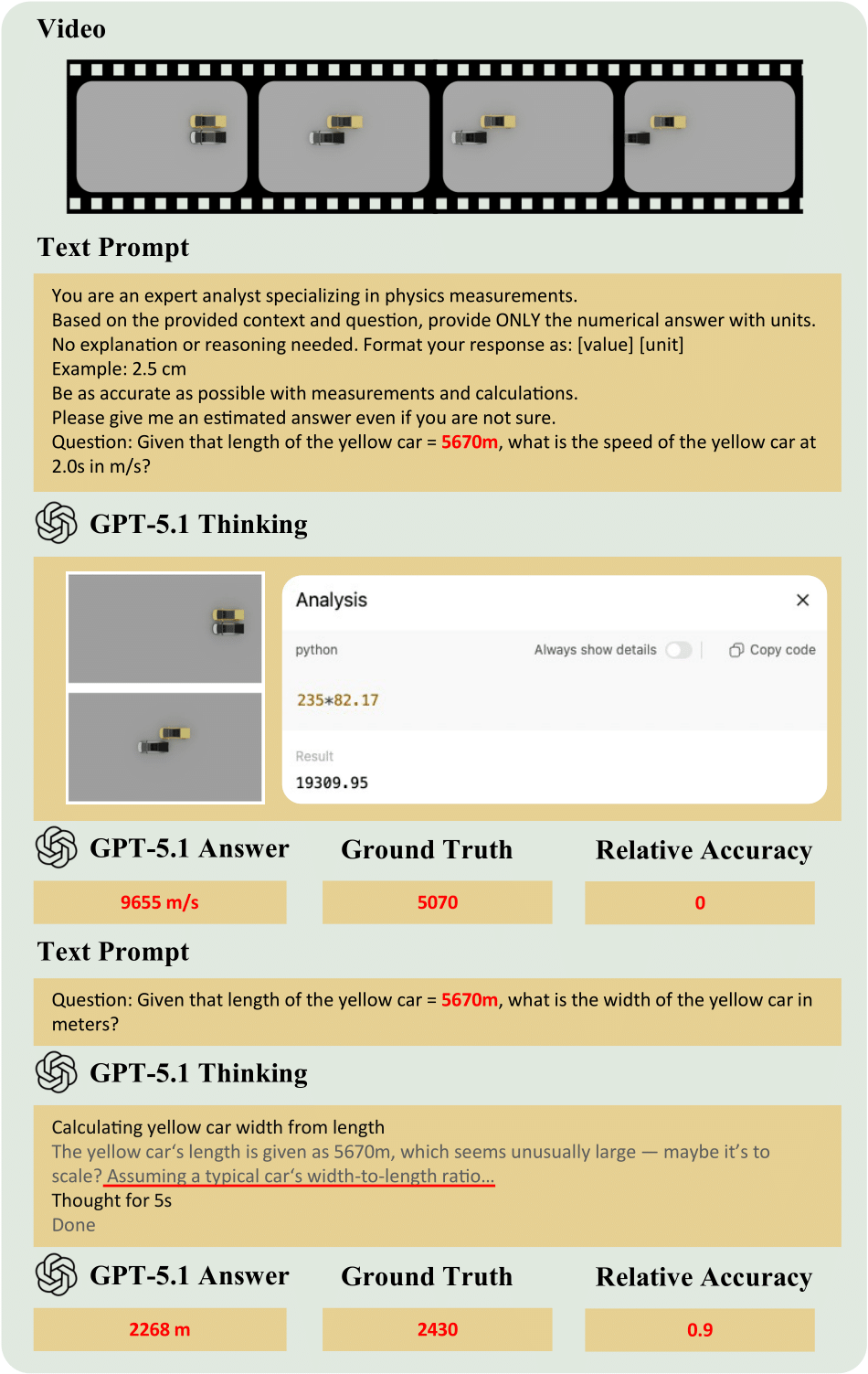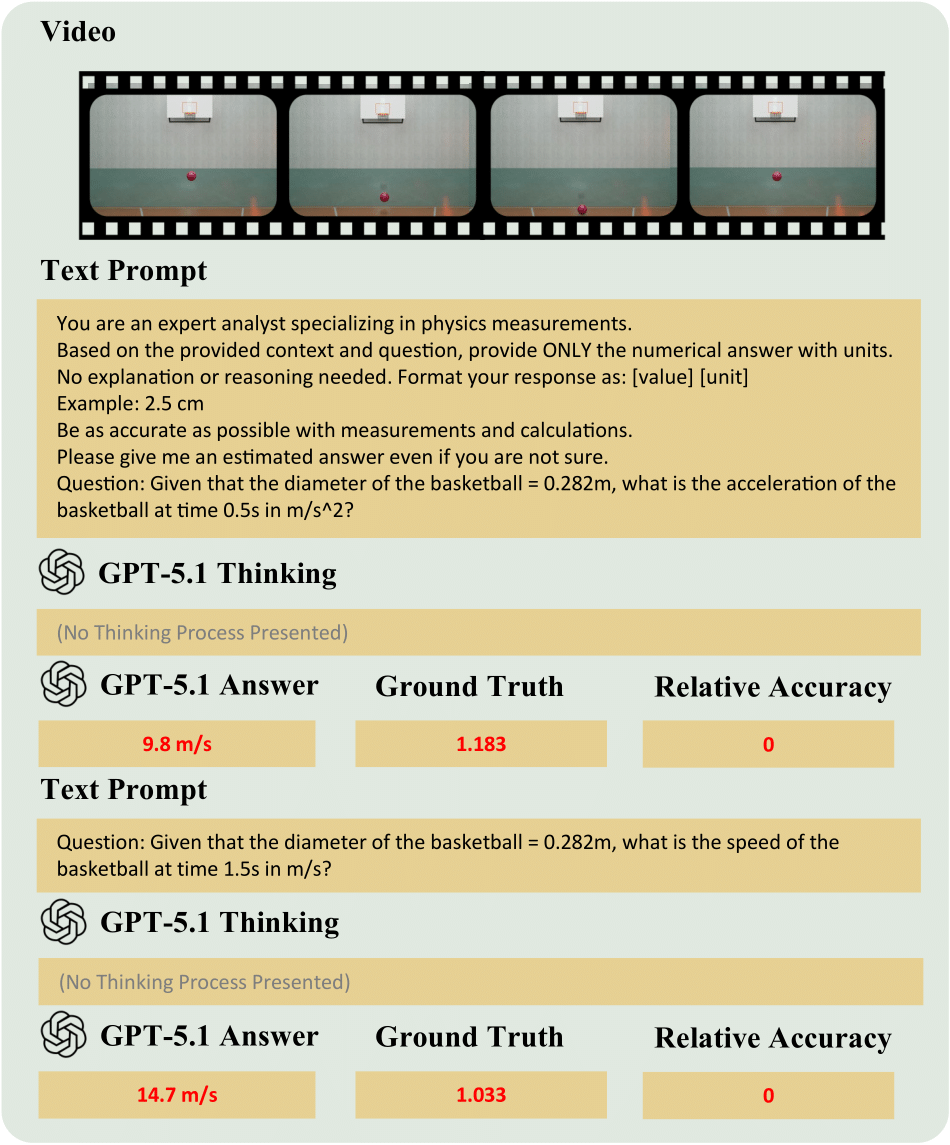
QuantiPhy introduces a rigorous benchmark for evaluating quantitative physical reasoning in Vision-Language Models. Unlike traditional VQA tasks that focus on qualitative descriptions, QuantiPhy challenges models to perform precise numerical inference grounded in physical laws.
-
🆕 Novel Task: Kinematic Inference
We formally define a task where object size, velocity, and acceleration are treated as mutually constraining quantities.
- Input: A video clip + A single physical prior provided as text (e.g., "The car is 4 meters long" or "Gravity is 9.8 m/s²").
- Reasoning: The model must use the provided prior to recover the world-to-pixel scale and leverage kinematic equations to deduce other unknown properties of the target object.
- Output: A precise numerical value (with units) for a target property (e.g., "The velocity at t=2s is 12.5 m/s").
-
🗂️ Structured Taxonomy
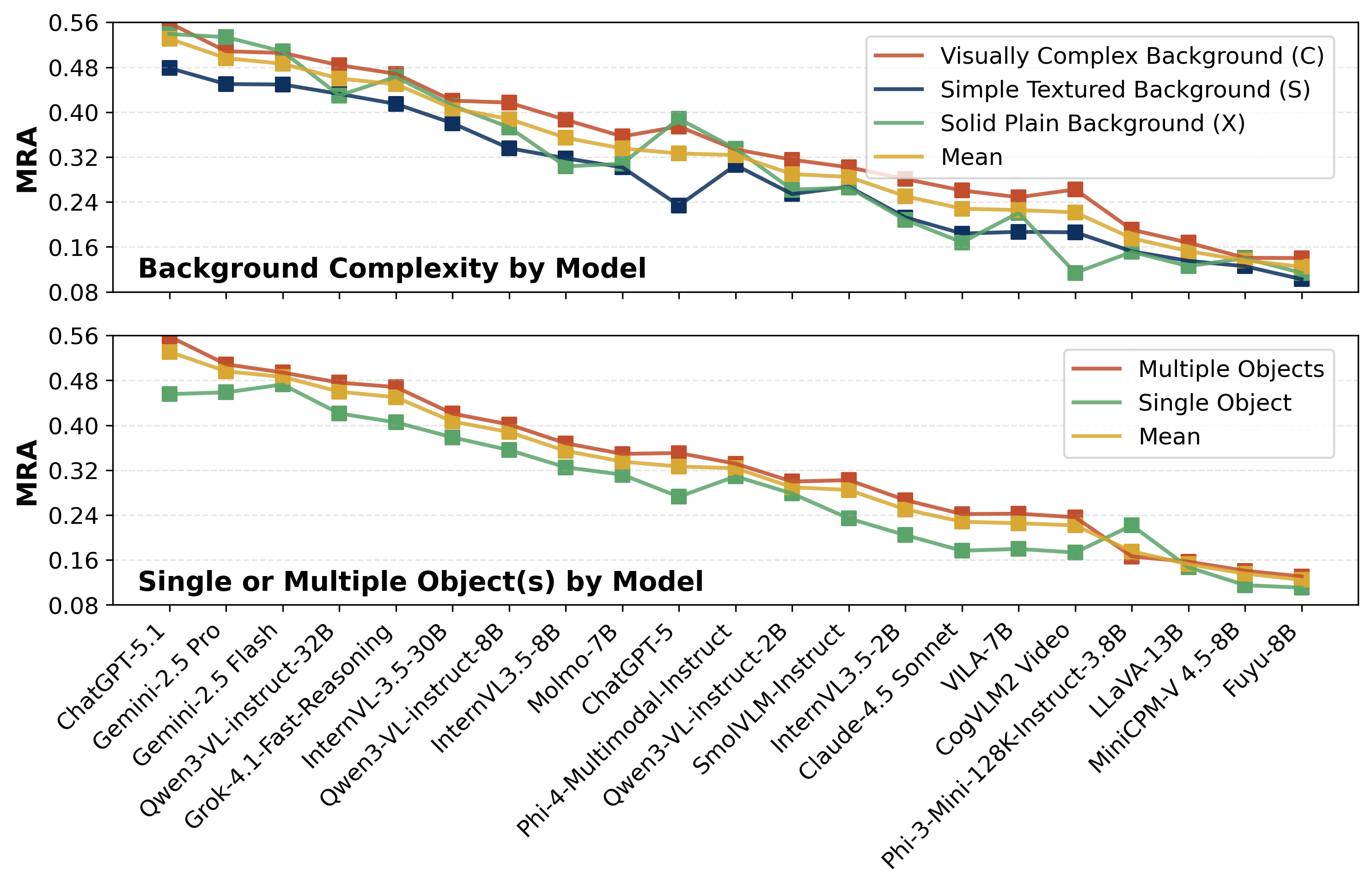
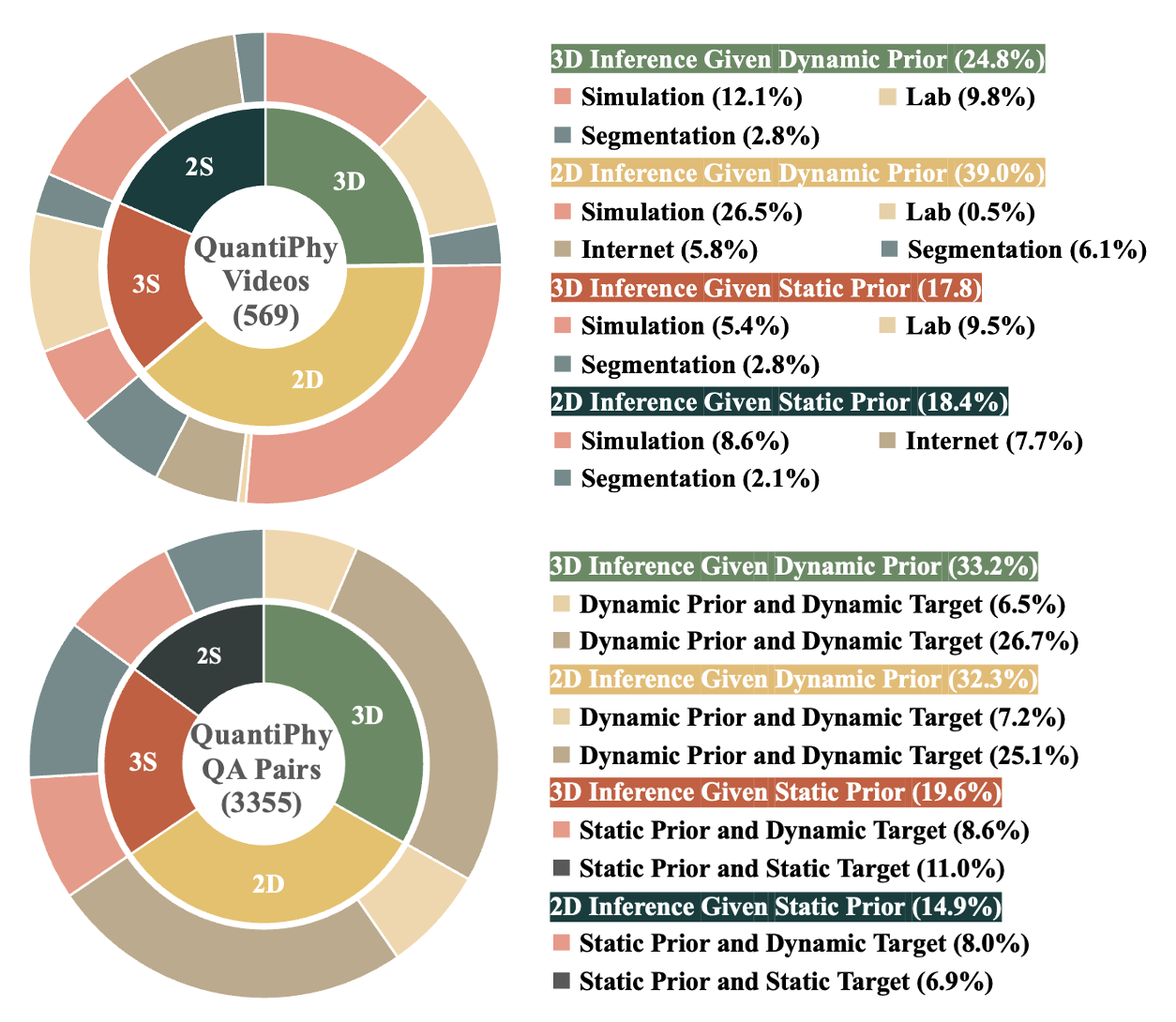
To provide fine-grained analysis of model capabilities, the benchmark is organized along two primary axes:
- Dimensionality: 2D (Planar motion) vs. 3D (Depth-varying motion).
- Physical Prior: Static (Size-based) vs. Dynamic (Motion-based, e.g., Velocity/Acceleration).
-
📊 Scale & Diversity
The dataset contains 3,355 video-question pairs derived from 569 unique videos. The data spans diverse sources (Simulation, Lab, Internet) to ensure coverage across microscopic, macroscopic, and astronomical scales.